
ChatGPTは便利なツールではありますが、有効な場面とそうでない場面は分かれます。
特に、社内での業務については社内ルールや業務プロセスなどを踏まえた対応が必要であり、ChatGPTが持つ一般的な知識だけでは難しいことも。
ChatGPTをうまく活用できない理由はどこにあるのでしょうか。社内で利用を促進していくためにはどのような取り組みが必要なのでしょうか。
この記事では、ChatGPTに関する当社の知見を踏まえ、このような課題に対して解説します。
Contents
ChatGPTとは
ChatGPTはOpenAI社が開発・提供している対話型のチャットサービスです。
2022年11月のリリース後からすぐにその有用性に注目が集まり、活用が進んでいます。
ChatGPTができること
以下では、ChatGPTが実現できることを簡単にご紹介します。
ChatGPTの具体的な活用事例については以下の記事でも紹介していますので、併せてご覧ください。
※関連記事:ChatGPTの国内・海外事例8選 ビジネス活用につなげるポイントとは
ChatGPTの活用率
業務の効率化や改善に活用できるChatGPTですが、社内での利用については進んでいないのが現状です。
ある調査※では、ChatGPTを「本格的に活用している」と回答した企業は11.5%、「試験的に活用している」と答えた企業も23.5%にとどまっているという結果もあります。
※参考:パーソル株式会社「ChatGPT活用状況レポート」より
また、ChatGPTを導入はしたものの、実際には利用していない、いわゆる「導入止まり」に陥っている企業も少なくないようです。
このように、まだまだ日本ではChatGPTの利用基盤が整っている企業が少ないほか、単にChatGPTを導入しても業務効率化といった目標を達成できるまでの十分な活用が出来ているケースが少ないのが実情です。
ChatGPTが社内で利用されない2つの理由
ChatGPTの社内利用が進んでいない背景にはどのような理由があるのでしょうか。
当社では、2つのChatGPTの性質が関係していると考えています。
①職種やタスクの性質がChatGPTとあっていない
そもそも、ChatGPTはあらゆる業務をカバーしてくれる魔法のツールではありません。
ChatGPTと相性がよい職種やタスクであるかどうかにより、うまく活用できるか変わってきます。
相性が良い職種やタスクを分けるポイントは、インターネット上に存在する一般的な情報で作業できるかどうかです。
たとえば、ITエンジニアであればコードの自動生成をお願いできます。
もしくは、データ分析をされる方であればエクセルやスプレッドシートでの集計・分析処理の提案をChatGPTにしてもらうことも可能です。
もちろん、ChatGPTが出力した内容が正しいとは限らないため、利用の際は出力結果を見極められるだけの技量は必要です。
それでも、業務を効率化できる余地は大きいといえます。
一方で、インターネット上に存在しない情報を基にする作業では、ChatGPTの活用は限定的なものとなります。
社内業務など社内のルールやプロセスに沿って仕事をしなければならない方にとっては、企画書の推敲やメール返信内容の原案など部分的にChatGPTを利用することはできますが、活用の幅は限定されます。
②ChatGPTが社内独自の業務に対応できない
ChatGPTは膨大なデータを学習していますが、それはあくまで公開されている一般情報のみです。
当然ながら、社内規程や業務ルール、ノウハウなどを学習しているわけではありません。
多くの仕事はインターネット上に存在する情報だけでは完結しないため、ChatGPTでの対応が難しいといえます。
一方で、社内のプロセスに沿った業務ほど業務効率化の改善余地があるのも事実です。
ChatGPTが社内のコンテキストを理解して対応してくれれば、このような業務も効率化できます。
しかし、このような社内独自の情報をChatGPTに習得させるには一定のエンジニアリングスキルが必要となります。
次項では、具体的にどのようなアクションが必要かを紹介していきます。
ChatGPTの活用率を上げるポイントは「RAG」
本項では、ChatGPTが利用されない理由の2つ目として上述した「②社内コンテキストを理解した対応をしてくれない」について深掘りしていきます。
ChatGPTに社内コンテキストを理解してもらうためには、具体的にどのような手法がとられるのでしょうか。
一般的に有効な手法として知られるのが検索拡張生成(Retrieval-Augmented Generation : RAG)です。
RAGを端的に言えば「ユーザーの質問と参照情報を一緒にChatGPTに与えて、参照情報を元にした回答を出力させる」という方法です。
具体的には、以下の流れで社内情報に基づく回答が可能となります。
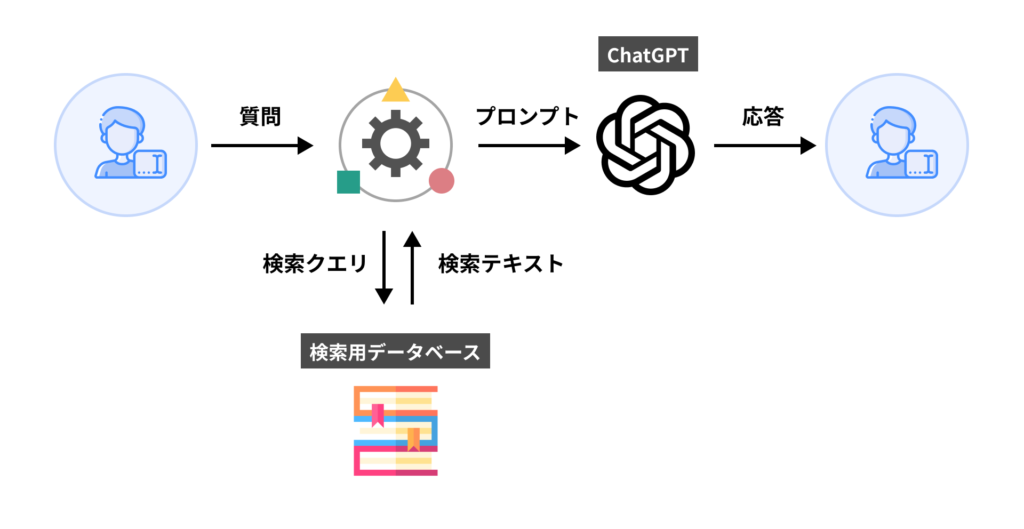
たとえばChatGPT Plusプランで利用できるGPTsでは「Knowledge」機能として、社内ドキュメントファイルをアップロードし登録するだけで簡単にRAGを利用できます。
ChatGPTから社内情報を踏まえた出力を得られれば、活用の幅も広がります。
RAGの利用におけるポイント
ここまでの説明から、RAGによる社内情報の利用は簡単にできると感じられるかもしれません。
しかし、その利用においてはいくつかポイントがあります。
ポイント1:セキュリティ
社内情報をアップロードする際には、セキュリティの担保が求められます。
たとえばChatGPTでは、ChatGPT PlusプランもしくはTeamプランではアップロードした情報はOpenAIのサーバーに保持されることとなります。
もちろん、セキュリティ面に問題があるわけではありませんが、社内のセキュリティ規程によっては利用できないケースもあります。
ポイント2:精度
弊社の経験も踏まえると、単純にドキュメントを丸ごとアップロードするだけでは十分な精度がでない可能性があります。
たとえば、社内の問い合わせに対して回答を生成するケースを想定します。
このとき、社内ドキュメントには問い合わせに関係のない情報も含まれます。
また、同じ内容が複数のドキュメントに書かれているなど、情報が重複しているケースもよくあります。
結果として、ChatGPTが実際の回答根拠となる部分以外も参照してしまい誤った回答を生成する可能性が高くなります。
LLM(Large Language Model:大規模言語モデル)は「最初と最後の情報を重要視し、中間情報は忘れやすい」という特性があるため※、大量の文章を渡すと情報が抜け落ちやすくなるのです。
この対策として、ドキュメントを丸ごとではなく、ある程度の意味の塊に区切るなどの前処理が重要となりますが、たとえばChatGPT Plusプランでは対応できない(2024年4月時点)といった問題もあります。
※参考:Lost in the Middle: How Language Models Use Long Contextsより
ポイント3:料金
OpenAIが提供するAPIを利用する場合には、文字数に比例したAPI利用料がかかります。
RAGにより大量にChatGPTにインプットを与えると、コストが高くなりがちです。
可能な限り余計な情報は送信しない方が費用を抑えられるため、上述した精度の問題と合わせて工夫が求められます。
参考:Fine-tuningについて
なお、本記事では社内情報などの独自情報を利用する方法としてRAGを紹介しましたが、同様の手法としてFine-tuningと呼ばれるものもあります。
Fine-tuningとは、簡単にまとめると、既にテキストデータを学習したモデルを基にして、特定のタスクや業界に合わせてさらに学習を進めることです。
ただ、弊社の経験と一般論※もふまえると、Fine-tuningでは気軽に独自情報に対する回答をさせることは難しいといえます。
RAGでは入力と独自情報を既存のLLMに渡しているだけで、既存のLLM自体には何も手を加えていませんが、Fine-tuningではLLM自体に追加でデータを学習させます。
学習データの準備、パラメータを調整しながら繰り返し学習データを用いた学習の実行、性能評価というサイクルを回す必要があり、かなりの時間とコストがかかります。
このような背景もあり、独自情報の検索においては広くRAGが利用されています。
※参考:Fine-Tuning or Retrieval? Comparing Knowledge Injection in LLMsより
まとめ
以上、この記事では「なぜ社内導入したChatGPTが使われないのか?」についてご紹介しました。
インターネットの公開情報を大量に学習しているChatGPTなどのLLMは、特定の職種やタスクにおいてはそのままの状態でも非常に心強い相棒となりえます。
一方で、多くの仕事は社内情報を利用するものであり、社内コンテキストを理解してくれないChatGPTでは限定的な利用しかできません。
そのため、広く社内の業務効率化を進めていくためにはRAGなどの仕組みを導入する必要があります。
なお、今回はChatGPTを取り上げましたが、ClaudeやGeminiなど他のLLMについても同様となります。
弊社では生成AI/GPT導入支援サービスを提供しております。
AzureやAWSなどで社内独自のインフラ環境を用意し、カスタマイズ性の高い社内GPT導入支援サービスを提供しております。
様々なデータの前処理の知見を活かし、精度の高い社内GPTの構築や独自性の高い用途への対応も可能となっております。
ChatGPTの活用を検討されている方は、お気軽にお声がけください。






About The Author
スパイスファクトリー公式
スパイスファクトリーは世界がより良い⽅向に向かうよう、変化を加速させる “触媒”(スパイス)としての役割を全うすることをミッションとしたDXエージェンシーです。最新テクノロジー、UIUX、アート、マーケティングなどの技術・メソッドを⽤いて、モノゴトを素早く、美しく、本質的に再定義し、幅広いクライアントのデジタルトランスフォーメーションを⽀援しています。